An experiment with using GPT to revamp Google Analytics - the end result, a lackluster product.
introducing GACopilot
Since I began using AI to revamp a calorie-tracking tool a few months ago and found it effective, I've been contemplating applying AI to more complex tasks. Like many others, I've been somewhat dissatisfied with the prevalent narrative of AI's potential to wreak havoc on the world, as well as the most common uses we see online: generating risqué images and promotional content.
In this article, I will share a practical example where AI capabilities are integrated with complex logic to create a more efficient tool. Throughout this process, I've encountered challenges, especially with multidimensional complexity in input and processing, that even the most advanced AI models struggle to address.
As a user of Google Analytics, a service often referred to as GA, By embedding a small piece of code, you can get a clear picture of your website's traffic, what your visitors are viewing, where they come from, and more.
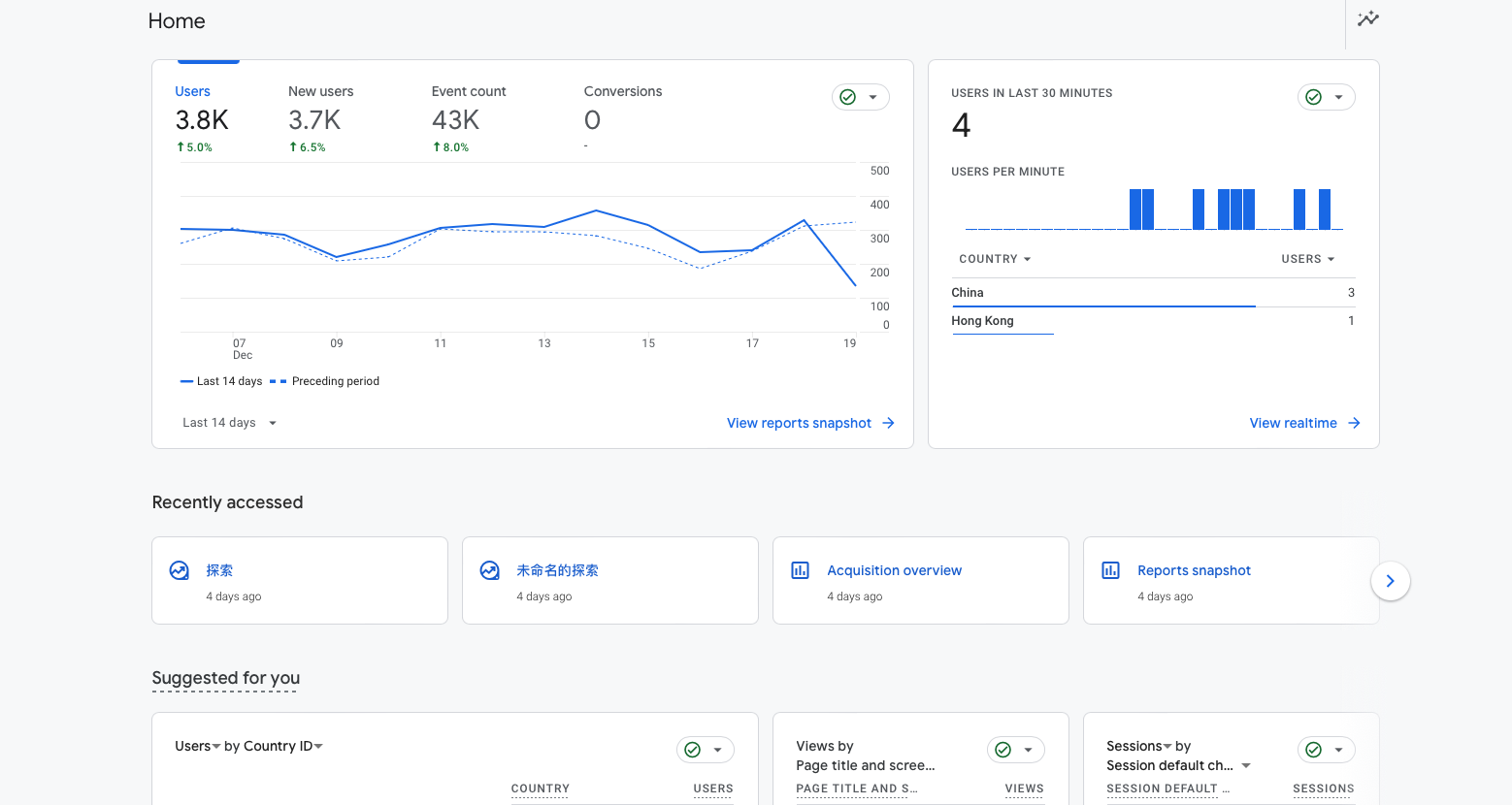
Last year, Google Analytics underwent a significant redesign, transitioning to GA4. This update was forward-thinking yet complex, leaving many long-time users bewildered. Familiar features disappeared, and generating specific data reports became a task requiring the creation of highly intricate pages.
Alongside GA4, Google also released new APIs that allow users to retrieve any desired data from GA. When I learned about OpenAI's release of the 'functions' feature, I realized I might be able to use AI to transform GA, making it more user-friendly.
My Idea
My idea was straightforward: a user would input the data they want to see, GPT functions would translate this into the necessary API calls to GA, and then the retrieved data would be rendered.
However, when I delved into GPT functions, I discovered significant limitations. The supported parameter types were mainly enumerations and strings. When I needed to pass parameters as arrays containing uncertain values from the enumerations, functions fell short.
What baffled me more was that, even when I specified values from the enumeration as per the documentation, GPT would occasionally 'hallucinate' and produce a string not listed in the enumeration.
Addressing these two issues consumed a lot of time. In reality, I couldn't 'solve' them but only 'circumvent' them. I manually wrote numerous rules based on Google's documentation to correct the model's output errors.
After completing these tasks, I managed to create a demo with the capability to display data directly based on a user's description, like so:
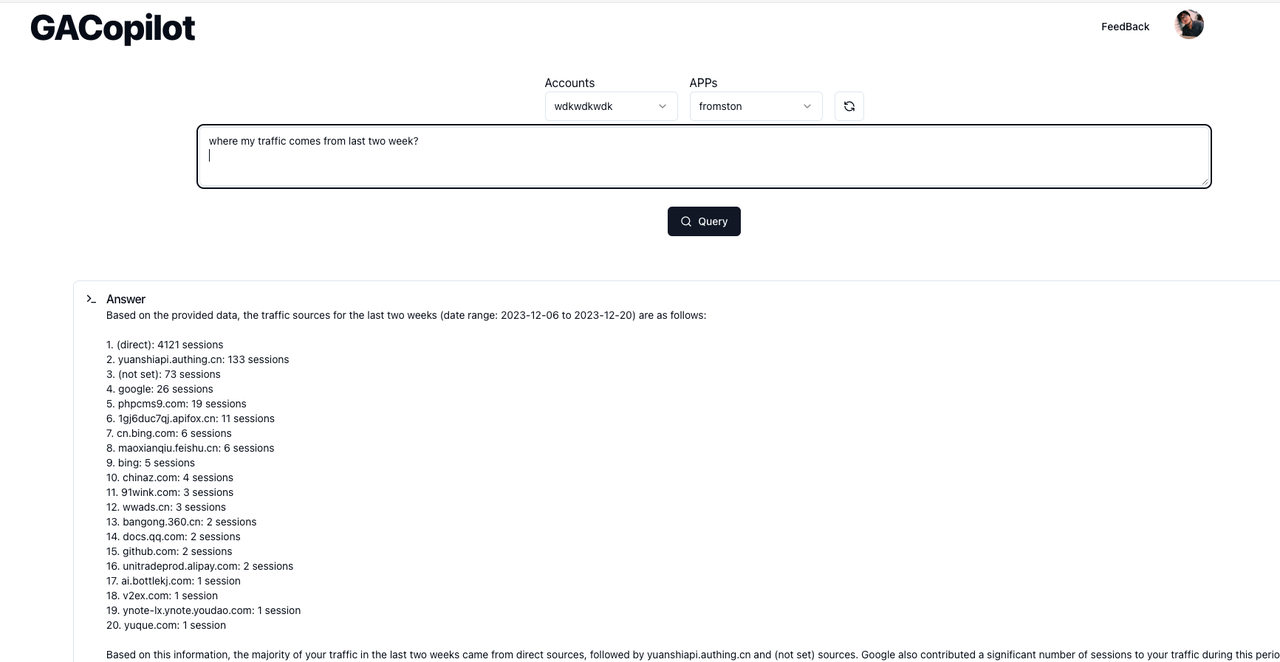
Developing this prototype required a tremendous amount of effort. I had to thoroughly review all of Google's APIs, and in this process, I came to understand the complexities of the APIs I was dealing with.
The core API of Google Analytics is 'runReport', with two primary parameters: 'dimension' and 'metric'. For instance, by setting 'city' as the dimension and 'total users' as the metric, one can obtain the number of users in each city.
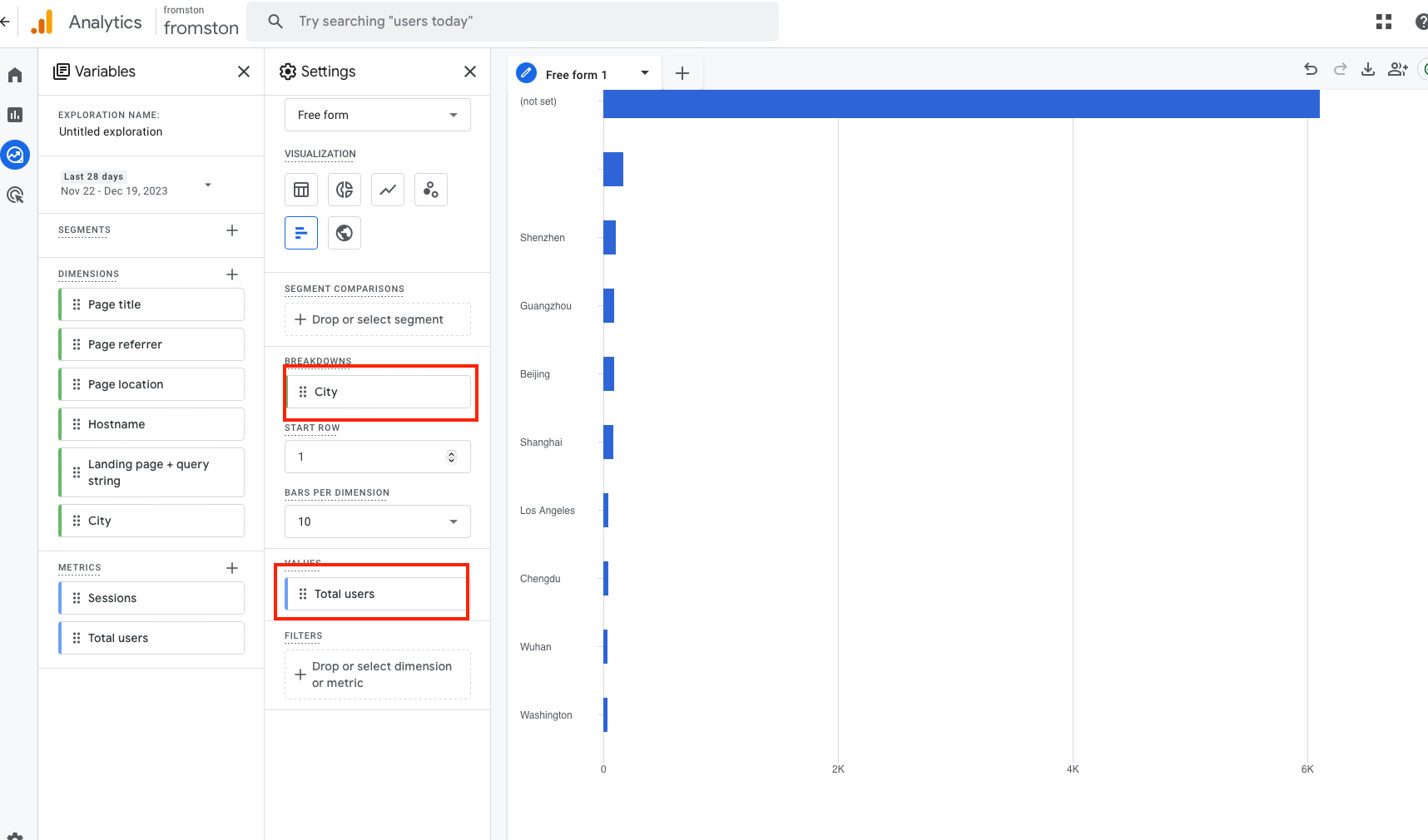
Google Analytics supports a wide array of dimensions and metrics, offering dozens of different types.
Introducing these metrics and dimensions to GPT and having it select the appropriate ones seemed feasible. However, I soon encountered more complex scenarios.
Complex Aspects
GA's interface allows for inputting multiple dimensions and metrics, resulting in multidimensional data. For example, if the dimensions are set to 'city' and 'date', and the metric is still 'total users', GA outputs the total users for each city on each day. To find out the number of users from Beijing on November 21, setting multiple dimensions appropriately will serve the purpose.
But this is just the first layer of complexity - multidimensionality and multiple metrics.
GA also supports a 'filter' parameter, which is both complex and powerful. It allows for filtering both dimensions and metrics, with various logical operators like AND/OR/NOT.
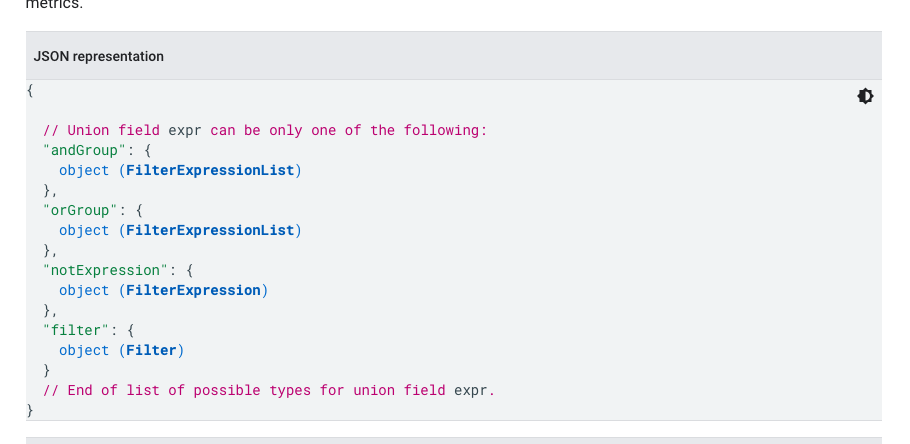
Within these logical operators, one can set match types and logic, and even use regular expressions.

In the previous example, to find out 'the number of users from Beijing on November 21', a simpler method would be to set the single dimension 'date', but filter for 'city includes Beijing'.
This introduces the second layer of complexity - control of filter logic.
Moreover, GA has another interface, 'batchRunReports', which allows fetching multiple reports simultaneously, each with its own dimensions, metrics, and filters, and then compiling them. This is particularly useful for complex requirements that necessitate aggregating data from multiple reports, representing the third layer of complexity.
While unraveling these APIs, I also experimented with GPT's capabilities. I found that even without touching the first type of complexity, GPT functions were already prone to errors. When tasked with setting multiple dimensions and parameters, the results were even more disappointing, despite using GPT-4, the most advanced large model to date.
GPT seems to handle only the simplest cases, like 'active users in the past week' or 'most popular pages'. These scenarios require just one dimension and one metric. However, if my requirements get slightly more complex, like 'which pages do users from Beijing prefer?', GPT is unlikely to provide the correct parameters.
To consider GPT foolish for these shortcomings would be an oversight. The task I set for GPT is essentially a complex data analysis task, involving:
- Understanding user queries and requirements.
- Selecting suitable fields and API usage methods.
- Accurately employing these fields to generate precise API calls.
These demands are far from simple. Someone who can manually extract data like 'which pages do users from Beijing prefer?' from GA, and further provide insights and conclusions, would theoretically qualify as a junior data analyst, capable of earning a decent salary.
Possible Solutions
Indeed, there are methods to enhance the effectiveness of this approach. One idea is to adopt an agent-based mindset, breaking down a query into multiple data retrieval tasks. Each task could utilize GPT functions to provide parameters for API execution, followed by an aggregation of the results. However, this process is overly complex and difficult to fully engineer, leading to a significant cost increase, making it currently impractical for project implementation.
Another strategy could involve fine-tuning GPT by feeding it data related to GA API documentation. Theoretically, this should make the model more familiar with the API and more likely to produce viable parameters. Yet, this approach is more costly, and as GPT-4 does not currently have a fine-tuning interface available, I haven’t tested it.
Consequently, after a week of working on this project, I realized its limitations: while it can convert spoken-word queries into direct data visualizations and conclusions, it falls short with more complex demands — the very reason I started this endeavor.
I've launched this product online with a payment plan, but I don't expect many people to be willing to pay for it at its current capability level. It only accesses the most superficial layer of data and offers surface-level conclusions and analyses. If you're interested, you're welcome to try it out:GACopilot
On the other hand, I have no doubt that with the advancement of model capabilities or the emergence of new modeling tools and approaches, this tool could become more useful. I'm convinced that the current issues can't be resolved simply through prompt engineering, making this a valuable direction for AI capability application.
This exploration reflects my view that large models have already started integrating into our daily lives, but we are still at a very early stage. More aspects of our lives will increasingly incorporate the capabilities of these large models. However, the journey to AGI or a model that could potentially pose existential risks to humanity is still a long way off.